| 乐思软件通过面向客户的软件开发过程捕获潜在用户的真正需求并准确理解,在开发之前形成系统设计模型说明书,像建造一栋大厦一样先勾画出软件的功能设计蓝图与界面设计蓝图,便于与用户一起沟通获取用户的反馈意见,以精确控制项目的范围与具体目标,提高用户的满意度。
乐思软件的软件开发流程遵循微软发布的微软解决方案框架3.1,以保证项目的稳定进行,成功完成。
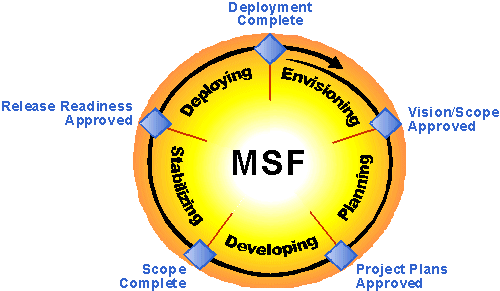
图1 微软解决方案框架
乐思软件通过的层次化组件化的方式设计企业应用软件并加以实现。客户端界面可以是Win32程序也可以是浏览器。
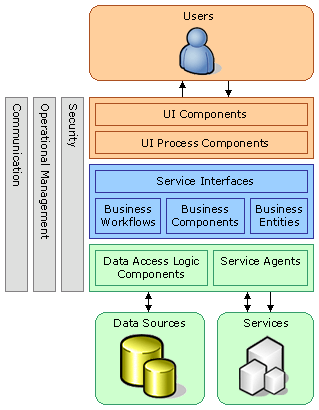
图2 企业应用软件的层次化组件化模型
|