
乐思网络信息采集系统
Web是一个巨大的资源宝库,目前页面数目已超过800亿,每小时还以惊人的速度增长,里面有你需要的大量有价值的信息,例如潜在客户的列表与联系信息,竞争产品的价格列表,实时金融新闻,供求信息,论文摘要等等。
可是由于关键信息都是以半结构化或自由文本形式存在于大量的HTML网页中,很难直接加以利用。
乐思软件的主要目标就是解决网络信息的采集问题。我们在这个问题上研究了8年也实践了8年,为国内外许多客户提供了几千次网络信息采集服务。在此基础上开发了乐思网络信息采集系统,目前居于国际领先水平(曾在国际招标中击败美国竞争对手)。
我们还针对仅需要单独应用的客户有针对性地推出了:
| 乐思新闻采集系统 乐思文本采集系统 乐思论坛采集系统 乐思RSS采集系统 (以上4种系统功能皆包含在乐思网络信息采集系统的任一版本中) 乐思网络信息实时采集开发包 (COM组件,用于简单采集) |
一、 主要功能
乐思网络信息采集系统的主要功能为:根据用户自定义的任务配置,批量而精确地抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。 如下图所示:乐knowlesys思
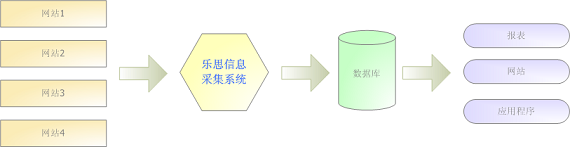
图1 乐思信息采集系统概念图
乐思网络信息采集系统除了可以处理远程网页外,还可以处理本地网页、远程或本地的文本文件。
乐思网络信息采集系统主要用于:舆情监测,品牌监测,价格监测,门户网站新闻采集,行业资讯采集,竞争情报获取,商业数据整合,市场研究,数据库营销等领域。aw禁止er盗用
二、 系统特点
本系统最大的特点是:采集方法的灵活性与采集数据的准确性
灵活性:任何复杂的查询与页面布局都可以灵活处理
准确性:结果数据高度准确(99%-100%)
♦ 对目标网站进行信息自动抓取,支持HTML页面内各种数据的采集,如文本信息,URL,数字,日期,图片等
♦ 用户对每类信息自定义来源与分类-采3453舆情4533集-
♦ 可以下载图片与各类文件a33lcc乐a思aw
♦ 支持用户名与密码自动登录
♦ 支持命令行格式,可以Windows任务计划器配合,定期抽取目标网站
♦ 支持记录唯一索引,避免相同信息重复入库
♦ 支持智能替换功能,可以将内容中嵌入的所有的无关部分如广告去除
♦ 支持多页面文章内容自动抽取与合并
♦ 支持下一页自动浏览功能 a33lcc乐a思aw
♦ 支持直接提交表单
♦ 支持模拟提交表单a33lcc乐a思aw
♦ 支持动作脚本
♦ 支持从一个页面中抽取多个数据表
♦ 支持数据的多种后期处理方式
♦ 数据直接进入数据库而不是文件中,因此与利用这些数据的网站程序或者桌面程序之间没有任何耦合
♦ 支持数据库表结构完全自定义,充分利用现有系统26禁止9盗用0
♦ 支持多个栏目的信息采集可用同一配置一对多处理
♦ 保证信息的完整性与准确性,绝不会出现乱码 26禁止9盗用0
♦ 支持所有主流数据库:MS SQL Server, Oracle, DB2, MySQL, Sybase, Interbase,
MS Access等
三、 运行环境
操作系统:Windows XP/NT/2000/2003/2008,建议采用Windows 2008 Server
CPU: 双核或四核CPU,3.0 G Hz以上
内存: 最低64M内存,建议2G或以上(如8G/16G/32G/64G)
硬盘: 最少20M空余硬盘空间,建议300G或500G
四、 行业应用
乐思网络信息采集系统在各个注重外部信息获取的行业都有着广泛的应用:
 门户网站
门户网站
可以做到:
每天自动采集指定网站(可达几百个,上千个)的最新内容(可以做到每天自动从上千个网络媒体采集上万条新闻信息)
每天自动采集指定购物网站产品价格信息(产品名称,说明,价格,图片等)
利益:
大大节约工作人员采集因特网信息的时间与精力,让他们有更多时间专注于业务问题
轻松实现行业信息整合
迅速提高本网站信息量与浏览量,同时提高Google排名与Alexa排名
轻松实现价格比较系统的前端采集子系统
新闻媒体
可以做到:
每天定时自动采集指定网站的新闻内容,扩大内容来源与数量
轻松整合不同地区与行业的新闻,形成专题
采集行业内的专业文章,论坛帖子,并进行整合
利益:
节约采编人员大量的时间,从而让他们可以有更多的精力来从事其他的事情
迅速提高本网站信息量与浏览量
轻松拥有海量信息输入
企业
可以做到:
实时而准确地采集国内外新闻,行业新闻,技术文章
实时而准确地采集竞争对手以及供应商的新闻,人事,产品,价格等信息数据抓取
实时而准确地采集公共信源的商业情报(同行产品价格,竞争对手的用户反馈,行业新闻)
实时而准确地采集本企业的品牌以及竞争对手的品牌在各大搜索引擎中的结果
实时而准确地采集各大行业论坛中的信息,从中了解消费者的需求与反馈,从而发现市场趋势与商业机会
准确地从网络公共信息中采集销售线索,潜在客户的资料
准确地从网络公共信息中采集本行业上万种产品的产品信息(描述,价格等),图片,技术文档。
利益:
快速而大量地获取目标商业信息,立刻提高公司的市场营销能力 数据挖掘
快速实现企业应用(ERP,CRM等)及企业门户网站对于因特网内容的整合
快速建立大容量专业知识数据库,立刻促进公司的知识管理水平
节约内部员工到各网站查阅新闻的时间
政府机关与军队
可以做到:
实时跟踪、采集与政府工作相关的国内外及地方新闻,政策法规,经济,产业等信息
解决与因特网隔离的重要部门对于因特网的信息需求问题 WA乐_思L监测SJ
解决政府主网站对各地级子网站的信息采集与整合问题
利益:
全面满足内部工作人员对外部因特网的实时信息的整合需求
迅速解决政务外网、政务内网的信息量不足,更新不及时问题
通过扩大信息量(如新闻,供求信息等)提高政务网站的用户满意度
大大节约工作人员采集因特网信息的时间与精力
广告与市场研究机构
可以做到:
快速而大量地获取公共信息中的商业名录资料网页抓取
快速而大量地获取目标网站的各种原始信息(例如Blog与BBS中的信息)到数据库中
利益:
快速形成特定群体的具有很高可信度的商业名录数据库 WA乐思采集SJ
快速形成用于分析统计与研究的用户反馈基础数据库
为品牌客户监视Blog与BBS上的相关信息
科学与技术研究单位
可以做到:
实时跟踪、采集相关的国内外科技信息与新闻
整合分布在各个网站网页上的科研数据,例如美国国家卫生研究院的生物科技信息中心公布的的大量基因相关数据
本地文本数据抽取
利益:
全面满足科研人员对于实时科技信息的整合浏览需求a网页抓取
从因特网的公开的可信来源轻松获取科学研究的相关数据WA乐_思L监测SJ
节约科研人员的极其宝贵的时间与精力
五、 版本功能区别
| 功能 |
标准版 |
专业版 |
企业版 |
| 微博网站采集 |
 |
|
|
| 论坛网站采集 |
|
|
|
| 博客网站采集 |
|
|
|
| 新闻网站采集 |
|
|
|
文本文件采集 |
|
|
|
RSS/XML抽取 |
|
|
|
图片网站采集 |
|
|
|
视频网站采集 |
|
|
|
社交网站采集 |
|
|
|
在线数据库网站采集 |
|
||
支持定时自动执行 |
|
|
|
静态URL列表抽取 |
|
|
|
动态URL列表抽取 |
|
|
|
网页屏幕快照 |
|
|
|
直接POST查询抽取 |
|
|
|
模拟填写表单查询抽取 |
|
||
高级数据处理 |
|
||
国外多语言信息采集 |
|
||
单项目表个数最大值 |
10 |
10 |
无限 |
字段个数最大值 |
60 |
100 |
无限 |
数据变形脚本最大行数 |
100 |
200 |
无限 |
连续抽取最大记录数 |
100,000 |
500,000 |
无限 |
使用时间 |
无限 |
无限 |
无限 |
网站数 |
无限 |
无限 |
无限 |
免费网站栏目配置个数 |
2 |
4 |
4 |
六、 演示与下载
在线观看各种类型的采集效果,更多详细请拨打电话(0755) 8603-2826联系我们。
欲获取更多信息或解决方案,请提交您的需求给我们或者直接发电子邮件到web2db@knowlesys.com。