
研发
目前,由于因特网的迅猛发展,国际上对于网络内容挖掘(Web Content Mining)与网络情报监测(Web Intelligence Monitoring)的研究越来越重视,研究者也越来越多。乐思软件以应用研究的角度,不断跟踪最新的理论成果与研究动向,不断学习实验融汇,开发出观念更新颖、功能更强大的信息处理工具软件。
领先的网络数据采集技术
我们的网络数据采集技术是建立在我们自己的理论与实践之上的。 我们自己的理论基于对全球范围内的网络信息采集研究学术论文的研究和我们的理论探索。 我们自己的实践便是多年从事网络数据采集服务分析处理上千个不同类型网站的实际经验。在研究初期,我们从以下几篇重要论文得到了启发:
大规模超文本搜索引擎Google的技术原理
The Anatomy of a Large-Scale Hypertextual Web Search Engine
该文为关于现代搜索引擎的经典论文,在1998年由还在Stanford的Google创始人Sergey Brin与Lawrence Page作为博士论文发表。文中提出两个重要技术:其一为将全球分散的因特网网页集中存储与索引的实现技术,其二为利用网页间相互链接的信息,网页内部的文本语义信息与结构信息来提高检索结果的质量。
从半结构化文本与自由格式文本中学习信息抽取规则
Learning Infomation Extraction Rules For Semi-Structured and Free Text
作者Stephen
Soderland为华盛顿州立大学计算机科学系教授。本文的被引用次数高达50多次。论文以信息抽取系统WHISK系统为例,描述了如何以机器学习的方式,利用小规模样本训练系统自动学习目标文本的抽取模式,从而实现自动化信息抽取的一种技术。这种技术不但极具启发意义而且很有实用价值。
从WWW中抽取模式与关系
Extracting Patterns and Relations from the World Wide Web
这是Sergey Brin的另外一篇力作。该论文提出一种叫DIPRE的方法,利用机器学习理论从大量文本中自动提取模式与关系。文中利用这种方法从互联网上分散的文本中提取图书信息,即作者,标题二元组。结果仅用了5本书的样本集,就自动扩展到了15,000本书,而且有些书是最大的网上书店亚马逊也没有的。
领先的软件工程
乐思软件通过面向客户的软件开发过程捕获潜在用户的真正需求并准确理解,在开发之前形成系统设计模型说明书,像建造一栋大厦一样先勾画出软件的功能设计蓝图与界面设计蓝图,便于与用户一起沟通获取用户的反馈意见,以精确控制项目的范围与具体目标,提高用户的满意度。 乐思软件的软件开发流程遵循微软发布的微软解决方案框架,以保证产品研发的稳定进行,成功完成。
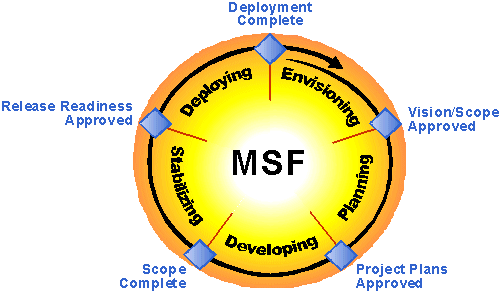
图1 微软解决方案框架
乐思软件通过的层次化组件化的方式设计产品应用软件并加以实现。
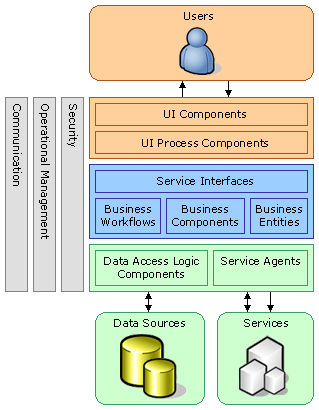
图2 应用软件的层次化组件化模型